


 行业动态
行业动态《食品科学》:湖北省农业科学院彭西甜研究员等:基于PLS与CNN的甘薯淀粉掺假鉴别及量化比较
甘薯,又称红薯、地瓜、红苕等,原产于热带地区,是一种兼具粮食、饲料和工业原料等多种用途的重要农作物。甘薯淀粉是从甘薯中提取,在食品、造纸、纺织等多个行业有着广泛应用。由于木薯淀粉和玉米淀粉价格较为低廉,而甘薯淀粉的价格普遍较高,因此,不少作坊和生产厂家在生产加工时,都用木薯淀粉、玉米淀粉、土豆淀粉等替代一部分红薯淀粉,以降低生产成本。
为解决淀粉及其制品中的掺假问题,近年来衍生出许多检测技术,主要包括形态学法、理化法、色谱法、质谱法、分子生物学法和光谱法等。
近红外光谱(NIR)是指波长介于可见光区与中红外区之间的电磁波,光谱波长范围为780~2526 nm,通过不同物质吸收光谱的不同能够获取食品成分中的特征信息而判断出物质类别及其含量,因其便捷、快速及无损的特性,广泛应用于食品中掺假问题的检测。
近年来,随着深度学习技术的蓬勃发展,卷积神经网络(CNN)作为人工神经网络与深度学习技术深度融合的新型算法,凭借其卓越的特征自动提取能力在相关领域广受关注。该方法通过模拟生物视觉感知机制,能够从复杂数据中高效提取深层次特征关联,已在光谱分析的特征提取与模式识别研究中展现出显著优势。
湖北省农业科学院农业质量标准与检测技术研究所的夏珍珍、彭西甜*和武汉大学化学与分子科学学院的张博源等人提出一种基于NIR和一维CNN(1D-CNN)的甘薯淀粉掺杂物分类和甘薯淀粉含量的定量方法,分别采集甘薯、玉米、土豆、木薯等纯薯类淀粉和以不同种类和比例制备的掺假甘薯淀粉原始光谱,然后运用一阶导数(1st)、连续小波变换(CWT)、多元散射校正(MSC)和标准正态变换(SNV)等预处理方法进行光谱处理,利用CNN算法将预处理前后的光谱作为1D-CNN的输入信号构建薯类淀粉分类模型和甘薯淀粉含量预测模型,并将光谱预处理前后的1D-CNN建模效果与传统的PLS建模结果进行比较,以期寻找到一种最优的甘薯淀粉掺假分类及含量量化的快速无损检测方法。

1.光谱分析
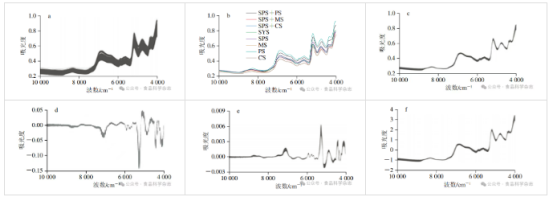

由图1a可知,各类淀粉光谱的变化趋势呈现出相似性,在8326、6848、6354、5876、5738、5610、5 183、4758、4384、4310 cm-1等波数处均存在吸收峰。其中,8326 cm-1处的吸收峰通常归因于C—H键的伸缩振动,特别是一级和二级醇中O—H键伸缩振动与C—H键弯曲振动的组合频带;6848 cm-1处的吸收峰可能源于C—H键的变形振动或苯环上C—H键面外弯曲振动;6354 cm-1处的吸收峰可能与N—H键的变形振动或C—H键的伸缩振动相关,尤其在含有氮元素的化合物(如氨基酸、胺类)中较为明显;5876 cm-1处的吸收峰可能涉及C—H键的伸缩振动或O—H键的二级倍频,在蛋白质中与酰胺V带密切相关;5738 cm-1处的吸收峰可能对应C—H键或O—H键的伸缩振动,常见于醇类或酚类化合物;5610 cm-1处的吸收峰主要与烷基链中C—H键的变形振动有关;5183 cm-1处的吸收峰可能由C—H键或N—H键的伸缩振动引起,多存在于含氮化合物中;4758 cm-1处的吸收峰可能源于长链烷基中C—H键的变形振动或伸缩振动;4384 cm-1处的吸收峰与饱和烃类化合物中C—H键的变形振动或伸缩振动相关;4310 cm-1处的吸收峰则主要与sp3杂化碳原子上C—H键的变形振动有关。
为进一步对比各类光谱的差异,对每类光谱数据绘制平均光谱图(图1b)。结果显示,不同种类的纯薯类淀粉光谱吸收峰位置基本一致,仅在吸收峰强度上存在差异。其中,土豆淀粉吸收峰的相对强度最高,甘薯淀粉次之,而木薯淀粉与玉米淀粉的吸收峰强度最低,且这两类淀粉的光谱特征较为相似。值得注意的是,甘薯淀粉与其他3类淀粉的吸收峰强度差异显著。尽管光谱谱峰蕴含了丰富的样品化学结构信息,但仅凭视觉观察难以准确解读,需借助化学计量学方法进行深入分析。
为有效消除样品光谱中的噪声、基线漂移及背景干扰,本研究采用1st、CWT、MSC和SNV4 种预处理方法对光谱数据进行处理。经CWT和1st处理后,样品光谱的漂移现象得到明显抑制(图1d、e),谱峰宽度显著减小;而通过MSC和SNV方法处理后,光谱峰的漂移问题同样得到有效改善(图1c、f)。
2.掺假薯类淀粉PCA
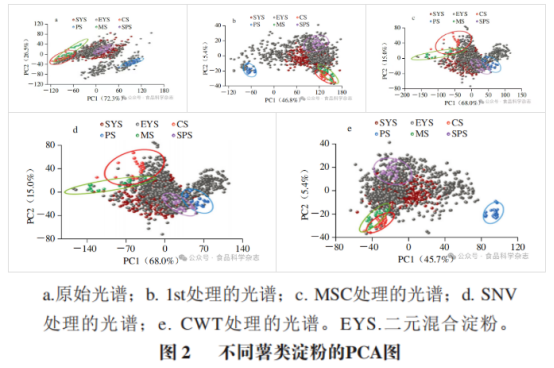
采用PCA方法构建不同薯类淀粉的鉴别模型。由图2a可知,在纯薯类淀粉体系中,甘薯淀粉和土豆淀粉的置信椭圆与玉米淀粉和木薯淀粉的置信椭圆呈现出明显的空间分离;然而,木薯淀粉与玉米淀粉的置信椭圆存在较大面积的重叠区域。这一结果表明,基于原始光谱的PCA,能够实现纯甘薯淀粉与其他种类淀粉的完全鉴别(鉴别准确率达100%)。在混合淀粉样品分析中,二元混合的甘薯淀粉样本与三元混合的甘薯淀粉样本置信椭圆高度重叠;同时,多元混合的甘薯淀粉样本与纯甘薯淀粉样本的置信椭圆亦存在显著重叠。该现象表明,当甘薯淀粉中掺杂其他种类淀粉形成混合物时,基于原始光谱的PCA方法无法有效实现对掺杂样品的准确鉴别。
采用1st和CWT预处理后,薯类淀粉的分类效果相较于原始光谱PCA结果有所提升(图2b、e),甘薯淀粉与土豆淀粉的置信椭圆间距增大,表明两类淀粉在特征空间中的区分度增强。然而,经MSC和SNV预处理后的数据,其PCA结果反而劣于原始光谱分析结果(图2c、d),如土豆淀粉与甘薯淀粉的置信椭圆出现局部重叠,这一现象揭示了SNV和MSC方法在去除噪声的同时,可能削弱了光谱中用于区分纯甘薯淀粉与土豆淀粉的关键差异信息。
以上结果表明,NIR结合不同的处理方法可以实现纯甘薯淀粉与其他种类淀粉的无损鉴别,但是不恰当的预处理方法会导致模型准确性下降。同时,仅靠PCA和光谱预处理无法进行多元混合甘薯淀粉的鉴别。因此,需要进一步探索其他的分类方法。
3.分类模型的建立和优化
3.1基于PLS方法的掺假淀粉鉴别
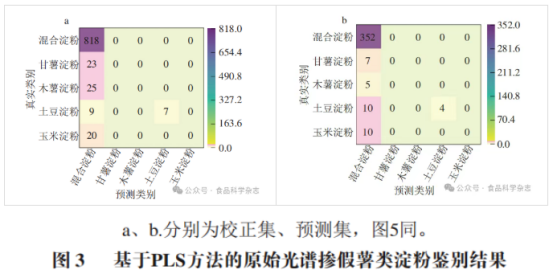
如图3所示,校正集中混合淀粉类样品的真阳样本数量为818个,预测集中为352个;土豆淀粉在校正集和预测集的真阳样本数分别为7个和4个;而甘薯淀粉、木薯淀粉及玉米淀粉在两个数据集中的真阳样本数均为0。表明基于PLS的原始光谱淀粉掺假预测模型仅对混合淀粉和土豆淀粉具有一定的预测能力,其适用范围存在明显局限性。
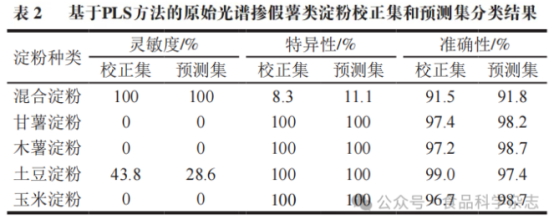
灵敏度用于表征模型对真阳样本的正确预测比例,特异性反映真阴样本的正确识别率,准确性则衡量所有样本正确分类的占比。如表2所示,尽管各类淀粉的整体正确率均超过90%,但进一步分析发现,甘薯淀粉、木薯淀粉、土豆淀粉及玉米淀粉的灵敏度表现欠佳,表明模型对这些种类淀粉掺假情况的识别能力较弱;同时,混合淀粉类样本的特异性较差,表明模型在区分混合淀粉与非掺假样本时存在一定误判风险。
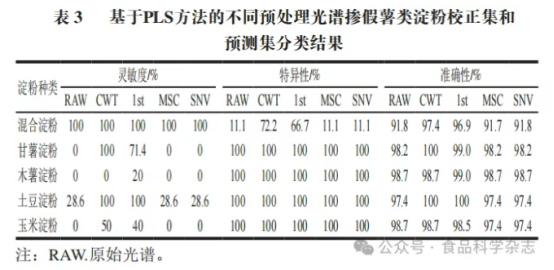
近红外原始光谱中往往存在背景干扰和噪声信号,这些因素会显著影响淀粉分类模型的最终预测结果。为降低预测误差、提升模型精度,通常将光谱预处理技术与分类算法相结合。采用CWT、1st、MSC和SNV4种预处理方法,对混合淀粉、甘薯淀粉、木薯淀粉、土豆淀粉及玉米淀粉进行处理,并评估其分类效果,相关统计结果见表3。不同光谱预处理方法对淀粉分类性能的改善程度存在差异。其中,CWT和1st方法的优化效果较为明显,而MSC和SNV方法的改善效果相对有限。CWT和1st方法主要通过消除原始光谱中的背景漂移误差,有效提升模型性能。具体来看,对于混合淀粉样本,经CWT和1st预处理后,模型灵敏度仍保持100%,对真阴样本的识别能力大幅提升,特异性分别从11.1%提高至72.2%和66.7%,整体预测准确性也相应提升至97.4%和96.9%。在甘薯淀粉和土豆淀粉样本中,CWT和1st处理使模型灵敏度显著提高,预测准确性提升1%~2%。然而,对于木薯淀粉和玉米淀粉样本,尽管光谱预处理在一定程度上改善了灵敏度指标,但模型对真阳样本的识别能力依然较弱。
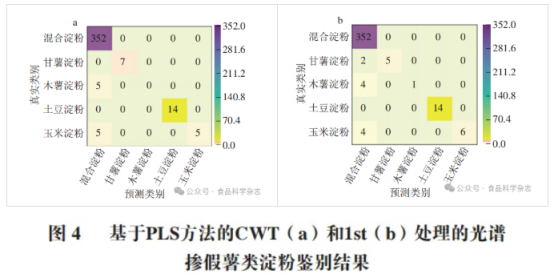
如图4所示,在预测集中,经CWT处理后,木薯淀粉和玉米淀粉的正确识别样本数分别为0和5,同时均存在5个假阴样本;经1st处理后,两类淀粉的正确识别样本数分别为1和6,假阴样本数则为4。上述结果表明,虽然结合PLS算法与光谱预处理技术可实现混合淀粉的高准确率预测,但在多类别淀粉的同时分类鉴别方面仍有待提高。
3.2基于1D-CNN方法的掺伪淀粉鉴别
CNN是一种典型的多层非全连接神经网络架构。在正向传播阶段,通过卷积层与池化层的交替运作,能够自动提取原始数据的层次化特征,卷积层利用卷积核对输入数据进行滑动卷积操作,实现局部特征的提取与抽象;池化层则通过下采样操作,在保留关键特征的同时降低数据维度,提升模型的泛化能力。反向传播过程中,CNN基于梯度下降算法,通过最小化损失函数计算各层参数的梯度,并据此更新网络权值,从而优化模型性能。本研究基于1D-CNN方法构建薯类淀粉分类模型。模型具体参数设置如下:在特征提取模块中,采用1个尺寸为2×1的卷积核;池化层选用2×1大小的池化核进行下采样操作。训练过程采用Adam优化算法进行梯度更新,设定训练轮次为500次,初始学习率为0.001,并引入L2正则化防止过拟合。此外,为实现动态调整学习率,设置学习率下降因子为0.1,当学习率降至0.0001时保持稳定。通过上述参数配置构建的1D-CNN模型,用于实现对不同种类薯类淀粉的分类识别。

基于原始光谱数据,采用1D-CNN方法对甘薯淀粉进行分类,结果如图5所示。在校正集样本中,薯类淀粉样品均实现正确分类,误判数为0;预测集样本中仅出现1 例误判,展现出较高的分类准确性。针对掺假薯类淀粉的分类性能评估结果见表4。在校正集样本中,混合类淀粉、甘薯淀粉、土豆淀粉和玉米淀粉的灵敏度、特异性和准确性均达到100%,表明该模型对校正集内5 类淀粉样本具有极佳的分类性能。在预测集样本中,混合淀粉、甘薯淀粉和土豆淀粉的灵敏度、特异性和准确性同样保持100%的优异表现;而木薯淀粉的特异性为99.7%,玉米淀粉的灵敏度为90%,这意味着木薯淀粉对真阴样本的正确识别率达99.7%,玉米淀粉对真阳样本的识别准确率为90%。此外,木薯淀粉和玉米淀粉的整体分类正确率均为99.7%,说明1D-CNN模型对这两类淀粉仍具备良好的预测能力。
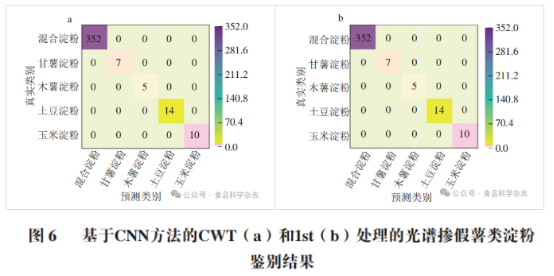
基于PLS的淀粉鉴别模型研究表明,CWT和1st两种光谱预处理方法能够有效去除原始光谱中的背景干扰与噪声信号,显著提升PLS分类模型的性能。基于此,选取经CWT和1st方法预处理后的光谱数据,构建基于1D-CNN的淀粉分类模型,对混合淀粉、甘薯淀粉、木薯淀粉、土豆淀粉及玉米淀粉进行分类研究。模型预测集的分类混淆矩阵如图6所示,在基于1D-CNN的5 类淀粉分类预测中,所有样品均实现正确分类,未出现误判情况。这充分表明,经光谱预处理后,基于1D-CNN的淀粉分类模型对5 类淀粉的预测正确率达到100%,展现出优异的分类性能和极高的准确性。
3.3PLS和1D-CNN分类结果比较
PLS作为经典的多变量统计分析方法,其核心在于对原始自变量进行降维,以此构建高效的分类模型;CNN作为深度学习领域的代表性算法,通过挖掘数据内在的可解释性特征实现精准分类。为系统评估两种方法在5类掺假淀粉分类中的应用效能,本研究对其分类表现展开深入对比分析。在原始光谱数据条件下,1D-CNN展现出优于PLS的分类性能。一方面,从分类覆盖范围来看,PLS分类模型仅能实现混合淀粉和土豆淀粉的鉴别,而1D-CNN模型则可同时对混合淀粉、甘薯淀粉、木薯淀粉、土豆淀粉及玉米淀粉进行有效分类。另一方面,在预测能力指标上,PLS模型对混合淀粉的假阴判别率仅为11.1%,对土豆淀粉的真阳判别率仅28.6%;与之形成鲜明对比的是,1D-CNN模型对5类淀粉的真阳率、假阴率及正确率均超过90%,分类性能优势明显。这表明在基于原始光谱的淀粉掺假鉴别中,1D-CNN较PLS具有更高的准确性和更广泛的适用性。
进一步对比光谱预处理后的模型性能发现,尽管CWT和1st预处理显著提升了PLS模型性能,但处理后的预测集中仍存在10个和8个误判样品;反观CNN模型,未经预处理时预测集仅有1个误判样品,经CWT和1st预处理后实现零误判。上述结果充分表明,无论是原始光谱还是预处理光谱数据,1D-CNN在淀粉掺假分类中的鉴别效果均优于PLS。此外,1D-CNN凭借强大的特征提取能力,可简化传统方法中复杂的光谱预处理流程,有效降低预处理难度。
4.定量模型的建立和比较
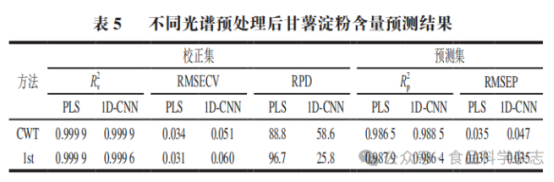
为比较PLS和1D-CNN方法在定量上的差异,挑选甘薯淀粉混合一种土豆淀粉为数据集,考察不同光谱预处理后甘薯淀粉含量预测结果,其结果见表5。对于PLS方法,校正集中的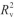 均为0.9999,RMSECV分别为0.034和0.031。结果表明,CWT和1st结果相当。同时,RPD值均大于3表示基于CWT和1st处理后的数据建立的甘薯淀粉含量模型均可用于精确定量。预测集中,CWT和1st处理后的
均为0.9999,RMSECV分别为0.034和0.031。结果表明,CWT和1st结果相当。同时,RPD值均大于3表示基于CWT和1st处理后的数据建立的甘薯淀粉含量模型均可用于精确定量。预测集中,CWT和1st处理后的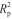 分别为0.9865和0.9879;RMSEP分别为0.035和0.033。比较预测集和校正集
分别为0.9865和0.9879;RMSEP分别为0.035和0.033。比较预测集和校正集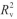 和
和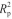 、RMSECV和RMSEP结果,二者结果比较相近,表明建立的PLS定量模型不存在过拟合现象。综上表明,基于CWT和1st光谱预处理后数据建立的PLS模型可以用于混合淀粉中甘薯淀粉含量的预测。
、RMSECV和RMSEP结果,二者结果比较相近,表明建立的PLS定量模型不存在过拟合现象。综上表明,基于CWT和1st光谱预处理后数据建立的PLS模型可以用于混合淀粉中甘薯淀粉含量的预测。
考察基于1D-CNN的定量模型结果发现,校正集中,通过CWT和1st光谱预处理之后,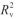 分别为0.9999和0.9996,RMSECV分别为0.051和0.060,RPD均大于3。预测集中,通过CWT和1st光谱预处理后,Rp2分别为0.9885和0.9864,RMSEP分别为0.047和0.035。结果表明,CWT和1st光谱预处理效果相当,均能准确预测混合淀粉中甘薯淀粉含量。
分别为0.9999和0.9996,RMSECV分别为0.051和0.060,RPD均大于3。预测集中,通过CWT和1st光谱预处理后,Rp2分别为0.9885和0.9864,RMSEP分别为0.047和0.035。结果表明,CWT和1st光谱预处理效果相当,均能准确预测混合淀粉中甘薯淀粉含量。
对比分析PLS和1D-CNN的预测结果,在校正集中CWT处理后的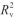 均为0.9999,RMSECV分别为0.034和0.051;1st处理后的Rv2分别为0.9999和0.9996,RMSEP分别为0.031和0.060,表明1D-CNN和PLS的预测结果相近。比较预测集中结果,PLS和1D-CNN两种方法的
均为0.9999,RMSECV分别为0.034和0.051;1st处理后的Rv2分别为0.9999和0.9996,RMSEP分别为0.031和0.060,表明1D-CNN和PLS的预测结果相近。比较预测集中结果,PLS和1D-CNN两种方法的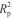 和RMSEP结果也相近。因此,两种方法均适用于混合淀粉中甘薯淀粉的含量预测。
和RMSEP结果也相近。因此,两种方法均适用于混合淀粉中甘薯淀粉的含量预测。
结论
本研究提出一种基于NIR的掺杂甘薯淀粉分类和甘薯淀粉含量定量的方法,并对PLS和CNN两种建模方法进行比较分析。研究结果表明,不同的光谱预处理方法可以不同程度地提高分类模型和定量模型的准确度,其中1st和CWT方法的分类效果要优于MSC和SNV方法。分类模型中,1D-CNN方法的预测精度优于PLS方法,预测集中,光谱预处理后1D-CNN方法对不同种类薯类淀粉的预测正确率提高至100%。定量模型中,PLS方法和1D-CNN方法均可实现单一混合淀粉掺假情况下甘薯淀粉含量的精准预测,而且PLS和1D-CNN模型的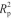 和RMSEP相近。与PLS方法相比,1D-CNN方法在分类上的效果要优于定量效果。本研究表明NIR、1D-CNN和PLS相结合可以实现掺假薯类淀粉的鉴别和其中甘薯淀粉含量的量化,对市场中薯类淀粉掺假的质量安全筛查具有重要意义。(DOI:10.7506/spkx1002-6630-20250506-014)
和RMSEP相近。与PLS方法相比,1D-CNN方法在分类上的效果要优于定量效果。本研究表明NIR、1D-CNN和PLS相结合可以实现掺假薯类淀粉的鉴别和其中甘薯淀粉含量的量化,对市场中薯类淀粉掺假的质量安全筛查具有重要意义。(DOI:10.7506/spkx1002-6630-20250506-014)


